


TL;DR
Ganz ohne komplexe Sonderlösungen können Sie mit „herkömmlichem“ PostgreSQL eine performante Vektordatenbank für KI-Anwendungen aufbauen. Spezialisierte Vector-Indizes sorgen dafür, dass Abfragen rasend schnell beantwortet werden. Das spart Ressourcen, sorgt für Responsiveness Ihrer KI-Systeme und Agenten und minimiert durch die Nutzung von Standardsoftware operative Risiken.
Vektordatenbanken und der Postgres-Ansatz
Moderne KI-Anwendungen – von Chatbots bis hin zu Knowledgebase-Systemen – setzen häufig auf Vektordatenbanken, um kontextbezogene Ähnlichkeiten zwischen Texten schnell zu erkennen. Statt jedoch ein separates Produkt wie einen „Vector Store“ als SAAS oder Self-Hosted-Lösung einzuführen, kann man diesen Ansatz auch mit PostgreSQL realisieren. Postgres bietet bereits eingebettete Vektordaten und hat sich in der Praxis als äußerst leistungsfähig erwiesen. Eine typische Struktur besteht dabei aus einer Tabelle, die pro Datensatz sowohl Fließtext als auch den dazugehörigen Vektor speichert.
Das ermöglicht folgende typische KI-Workflows:
- Die Anwendung (z. B. ein Chatbot) reicht eine Suchanfrage als Vektor ein.
- PostgreSQL berechnet mithilfe von Cosine Similarity oder anderen Metriken, welche Einträge im Datenbestand den höchsten inhaltlichen „Match“ aufweisen.
- Relevante Dokumente oder Ausschnitte werden an das KI-Modell zurückgegeben, um eine fundierte Antwort zu generieren.
Warum Indizes entscheidend sind
Sobald man mehrere hunderttausend (oder mehr) Embeddings in der Datenbank hat, wird Performance zum Schlüsselfaktor. Bei einem unserer Kundenprojekte gab es beispielsweise bei rund 600.000 Einträgen deutliche Performance-Einbußen, wenn wir keine geeigneten Indizes genutzt hätten.
- Vector-Index: Für die Vektorsuche (z. B. Cosine Similarity) braucht man spezialisierte Indizes, damit nicht jedes Mal die gesamte Tabelle gescannt wird.
- Mehrere spezialisierte Indizes je nach Kategorie: Bei verschiedenen Datenkategorien ist es in der Regel sinnvoll sein, pro Kategorie einen eigenen Index zu nutzen, um die mögliche Datengrundlage gezielt einzuschränken und so die Antwortzeiten weiter zu reduzieren.
Ein praktisches Beispiel: Sobald in der SQL-Abfrage bestimmte Filterkriterien auf ENUM-Basis wie etwa „Inhaltstyp = Event“ hinzukommen, entscheidet PostgreSQL, welcher Index verwendet werden soll. Der Clou: Liegen mehrere, angelegte Vector-Indizes vor, wählt das DB-Management-System in der Regel automatisch den effizientesten Index aus.
GIN-Indices optimieren JSON-Abfragen und verhindern Parallel Scans
In KI-Anwendungen wird häufig mit Metadaten in Form von JSON-Objekten gearbeitet (z. B. Dokumenten-IDs, Kategorien oder Statusfeldern). Beim Abfragen bedeutet das üblicherweise, dass man Teile oder auf Felder dieses JSON-Objekts filtern möchte.
Ohne Index wird das zu einem sogenannten Parallel Scan über alle Datensätze führen, was bedeutet: bereits bei einigen Hunderttausend Einträgen erhöht sich die Abfragezeit drastisch.
Die Lösung für effiziente JSON-Anfragnen ist der GIN-Index (Generierter Inverted Index). GIN unterstützt diverse Operatoren für JSON-Daten, etwa das Containment-Operator @> (enthält eine bestimmte Teilstruktur). Nachdem wir einen solchen Index angelegt hatten, konnten wir die Bearbeitungszeit für die gleiche Abfrage von mehreren Sekunden auf wenige Millisekunden reduzieren.
„EXPLAIN ANALYZE“ – Erst analysieren, dann optimieren!
Bevor Sie allerdings Indizes konfigurieren, sollten Sie herausfinden, wo das eigentliche Bottleneck liegt. Hier kommt der SQL-BEFEHL „EXPLAIN ANALYZE“ ins Spiel. Es zeigt Ihnen, ob überhaupt ein Index genutzt wird, wie viele Reihen gescannt werden und wie lange die Abfrage in jedem Ausführungsschritt dauert.
Zwei Beispiele zum weiteren Verständnis:
- Index Scan: Zeigt, dass ein vorhandener Index tatsächlich verwendet wird. Die Abfragezeiten sind kurz, da PostgreSQL nur die relevanten Datensätze einliest.
- Parallel Scan: Warnsignal! Wenn die Datenbank alles parallel durchsuchen muss, weil kein passender Index existiert, steigt die Laufzeit schnell an.
Monitoring in der Cloud
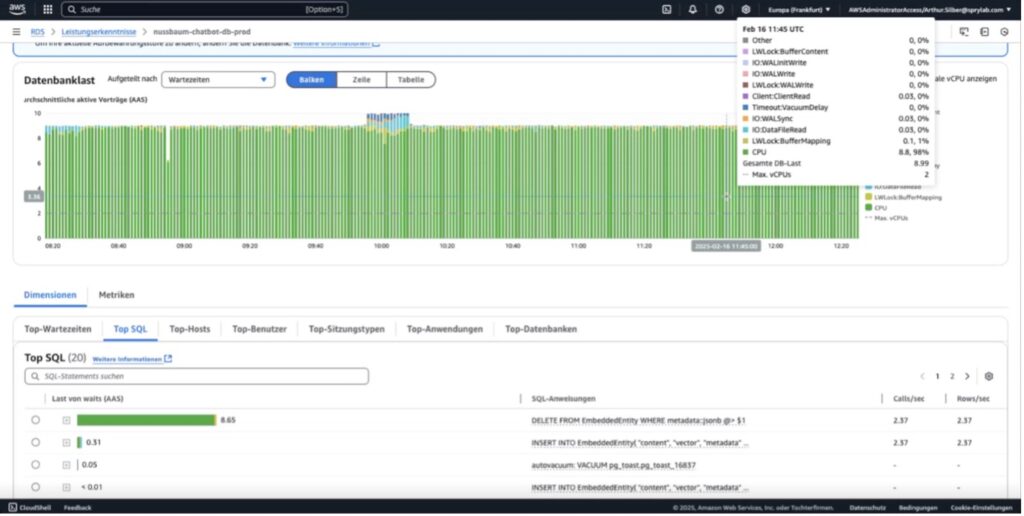
Wenn Sie PostgreSQL in AWS oder einem anderen Cloud-Anbieter laufen lassen, können Sie im Dashboard schnell erkennen, ob die CPU-Auslastung dauerhaft hoch ist oder ob Sie Speicherlimits erreichen. Deuten die Metriken auf einen Engpass hin, sollten Sie:
- Identifizieren, welche Queries die Last verursachen (oft sind es wenige „Heavy Queries“).
- Prüfen, ob fehlende Indizes oder unoptimierte Operatoren (z. B. JSON-Contains) das Problem sind.
- Anpassungen testen und erneut mit „Explain Analyze“ oder Cloud-Monitoring-Auswertungen nachmessen.
Fazit
Mit spezialisierten (und mehreren!) Vektor-Idices sowie GIN-Indices auf JSON-Datenstrukturen lässt sich PostgreSQL produktiv als Vektordatenbank nutzen. Dieser Ansatz eignet sich besonders dann für Sie, wenn Sie bereits auf PostgreSQL setzen und das System administrativ im Griff haben – denn somit müssen Sie sich keine weitere Technologie ins Haus holen.
Wenn Sie bei der Konzeption und Entwicklung Ihrer individuellen KI-Lösung Unterstützung benötigen, besuchen Sie unsere KI-Leistungsseite für detaillierte Informationen und lassen Sie sich von unseren Expert:innen beraten.







