


TL;DR
Erfahren Sie, wie die /llms.txt Datei Ihre Website für KI-Systeme optimiert. Die Reise geht hin zu llms.txt, um komplexe Websites wie Kundenportale GEO-ready zu machen. Während traditionelle SEO-Standards wie robots.txt Suchmaschinen leiten, fungiert /llms.txt als kuratierte Schatzkarte für Large Language Models. Statt Inhalte zu blockieren, zeigt sie KI-Systemen den direkten Weg zu Ihren wertvollsten Ressourcen. Besonders für umfangreiche Plattformen und Portale mit hunderten Artikeln und Unterseiten wird diese Markdown-Datei zum Pflichtprogramm. Sie löst das Kontextfenster-Problem moderner KIs und macht Ihre Inhalte gezielt auffindbar – genau dann, wenn ChatGPT, Perplexity oder andere KI-Tools nach Antworten suchen. In unseren Content-lastigen Kundenprojekten beachten wir die folgenden Best Practices bereits.
Der technische Paradigmenwechsel: Von SEO zu GEO
Als Entwickler:innen kennen wir das Problem aus unseren Kundenprojekten: Moderne Websites sind komplexe Konstrukte aus HTML, JavaScript, dynamischen Inhalten und verschachtelten Navigationsstrukturen. Für Large Language Models (LLMs) bedeutet das eine massive Herausforderung. Die Token-Limits aktueller Modelle zwingen uns zum Umdenken – nicht mehr alle Inhalte sind gleich wichtig, sondern wir müssen kuratieren und priorisieren. Dabei geht die Reise klar in Richtung llms.txt als neuen Standard für GEO-ready Portale.
Die /llms.txt Datei ist dabei kein weiteres Compliance-Tool wie robots.txt. Während robots.txt Crawler instruiert, welche Bereiche einer Website besucht werden dürfen, und sitemap.xml alle URLs für die Indexierung auflistet, verfolgt /llms.txt einen fundamental anderen Ansatz: Sie ist eine Kurationsdatei für Inference-Time-Zugriffe.
Das Format verstehen
Die Datei nutzt bewusst Markdown statt XML oder JSON – das ist entscheidend, da LLMs mit Markdown-strukturierten Inhalten optimal arbeiten können. Die Spezifikation, die wir in unseren Projekten anwenden, sieht folgende Struktur vor:
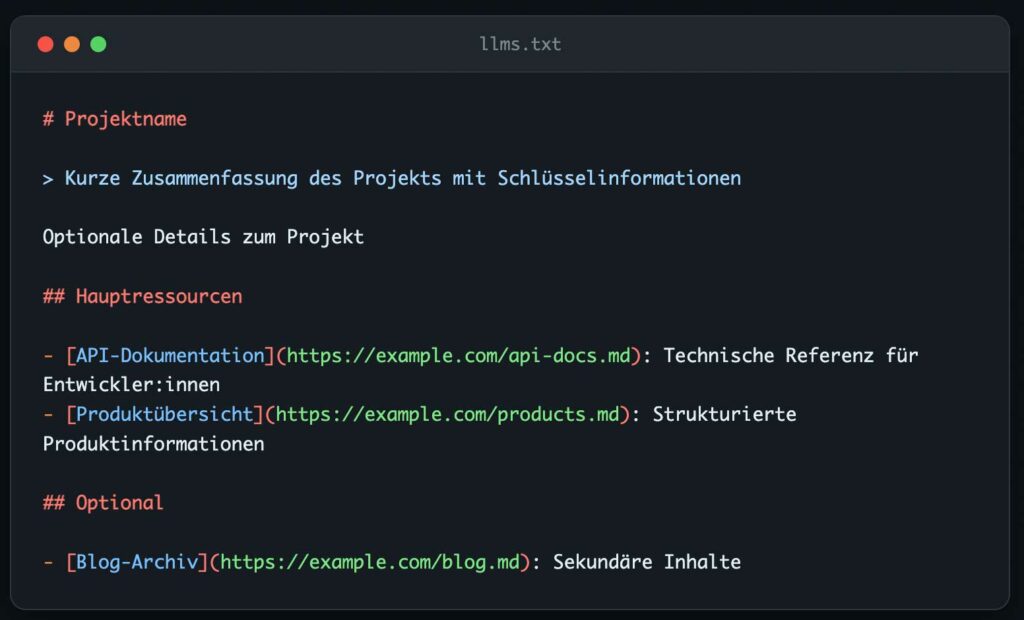
Technische Implementierung für Content-lastige Projekte: Unsere Best Practices
Für komplexe Website-Projekte mit tausenden oder hunderten Artikeln (übrigens nicht nur für unsere Verlagsfokusbranche relevant) haben wir bei SPRYLAB spezifische Best Practices entwickelt:
1. Content-Priorisierung: Nicht jeder Ihrer Artikel ist gleichwertig für KI-Systeme. In unseren Kundenprojekten nutzen wir die /llms.txt, um die relevantesten Artikel zu markieren – jene mit klarer Struktur, semantischen Markierungen und hohem Informationsgehalt.
2. Markdown-Bereitstellung: Die Spezifikation empfiehlt, für jede wichtige Seite eine .md-Version bereitzustellen. Bei einer URL wie https://portal.example.com/kb/installation-guide würde die Markdown-Version unter https://portal.example.com/kb/installation-guide.md erreichbar sein. Diese Struktur setzen wir standardmäßig in unseren Content-Management-Systemen um.
3. Strukturierte Daten nutzen: LLM-freundlicher Content bedeutet für unsere Kundenprojekte:
- Kurze, scannbare Absätze
- Klare H1-H3 Hierarchien
- Listen und Tabellen statt Fließtext
- Semantische Hinweise wie „Schritt 1:“, „Zusammenfassung:“, „Kernaussage:“
Der Unterschied macht’s: Crawling vs. Inference
Ein kritischer Punkt, den wir in unserer Beratung immer wieder betonen: /llms.txt wird nicht für das Training von KI-Modellen verwendet, sondern für Inference-Time-Zugriffe. Wenn Nutzende ChatGPT nach Informationen zu Ihrem Produkt fragen, kann das Modell in Echtzeit auf Ihre /llms.txt zugreifen und die kuratierten Inhalte abrufen.
Das bedeutet für Sie konkret:
- Keine Beeinflussung des Modell-Trainings
- Echtzeit-Zugriff bei Nutzeranfragen
- Direkte Verlinkung zu relevanten Ressourcen
- Umgehung von Navigationshürden und JavaScript-Barrieren
Praktische Überlegungen für große Plattformen: Lessons Learned aus unseren Projekten
Bei der Implementierung für Projekte mir einer großen Anzahl an Inhalten priorisieren wir vor allem folgende drei Punkte:
Hosting-Kompatibilität: Nicht alle Hosting-Provider unterstützen KI-Bot-Zugriffe. In unseren Enterprise-Projekten stellen wir sicher, dass die Infrastruktur KI-ready ist.
Content-Transformation: Wir nutzen Web-Scraping-APIs und eigene Tools, um bestehende HTML-Inhalte automatisiert in saubere Markdown-Strukturen zu konvertieren. Tools wie das llms_txt2ctx CLI-Tool expandieren /llms.txt Dateien in vollständige Kontext-Dateien.
Versionierung: Bei häufigen Content-Updates implementieren wir eine Versionskontrolle der /llms.txt Datei. Die FastHTML-Dokumentation zeigt exemplarisch, wie automatisierte Pipelines die Markdown-Versionen synchron halten – ein Ansatz, den wir erfolgreich adaptiert haben.
Integration in bestehende Architekturen: So machen wir Ihre Plattform GEO-ready
Die /llms.txt Datei ergänzt bestehende Standards, ersetzt sie aber nicht. In unseren Kundenprojekten zeigt sich:
| Dateityp | Funktion | Anwendungsfall in unseren Projekten |
|---|---|---|
| robots.txt | Crawler-Kontrolle | Weiterhin essentiell für klassisches SEO |
| sitemap.xml | URL-Discovery | Bleibt Basis für Crawl-Priorisierung |
| /llms.txt | KI-Kuration | Neue Schlüsselkomponente für GEO |
Für Entwicklungsteams bedeutet das: Die /llms.txt kann parallel zu bestehenden SEO-Maßnahmen implementiert werden, ohne Legacy-Systeme anzupassen – ein Ansatz, den wir bereits erfolgreich in Migrationsprojekten umgesetzt haben.
Fazit
Die Reise geht klar in Richtung llms.txt und bei SPRYLAB sind wir mittendrin. Als Spezialist für individuelle Plattform-Lösungen und komplexe, anspruchsvolle Websites integrieren wir diese Best Practices schon standardmäßig in unsere Content-lastigen Projekte. Die Ära der Generative Engine Optimization (GEO) hat begonnen, und wir sorgen dafür, dass Ihre komplexen Portale und Websites dafür gerüstet sind.
Ob umfangreiches Kundenportal, technische Dokumentationsplattform oder wissensintensive Unternehmenswebsite – wir machen Ihre digitalen Inhalte nicht nur für Menschen, sondern auch für KI-Systeme optimal zugänglich.
Sie haben eine Idee für ein nächstes Digitalprojekte bei dem die großen LLMs auch Ihre Inhalte auffinden sollen? Dann buchen Sie jetzt ein kostenloses Erstgespräch mit einem unserer technischen Expert:innen.







