


Im digitalen Zeitalter sind Daten der Schlüssel zu Ihrem Erfolg. Um sie effizient zu verwalten, zu analysieren und in wertvolle Erkenntnisse zu verwandeln, benötigt Ihr Unternehmen leistungsstarke Tools. KI-basierte Systeme wie RAG Chatbots (Retrieval Augmented Generation) und KI-Assistenten ermöglichen es Ihnen, auf Datenquellen in bisher unerreichter Geschwindigkeit und Präzision zuzugreifen. Ob im Sales, Support oder zur Wissensaufbereitung – sie bieten enormes Potenzial, Ihre Unternehmensprozesse grundlegend zu transformieren. In diesem Blogbeitrag möchte ich die Funktionsweise und den Mehrwert von RAG Chatbots und KI-Assistenten genauer beleuchten.
Wie funktioniert Retrieval Augmented Generation?
Retrieval Augmented Generation, kurz RAG, kombiniert die Leistungsfähigkeit von großen Sprachmodellen (LLMs) mit einer Suchkomponente. Ein zentraler Vorteil dieser Technik ist, dass das LLM nicht selbst umfangreich und kostenintensiv trainiert werden muss. Stattdessen greift es auf von Ihnen definierte externe Datenquellen zu, um relevante Informationen zu extrahieren und in die generierte Antwort einzubinden. RAG Chatbots und KI-Assistenten nutzen also das Sprachverständnis von generativen KIs, während Sie die Datenbasis bereitstellen.
Der RAG-Prozess lässt sich in drei Schritte unterteilen:

- Query: Eine Anfrage wird in Form eines Keywords oder Satzes gestellt, um die Suchrichtung zu definieren.
- Search & Retrieval: In festgelegten Quellen, z. B. Datenbanken oder Textdokumenten, werden passende Inhalte gesucht. Diese können Textdokumente, OCR-verarbeitete Bilder, PDFs, Videos oder Websites sein. Ergebnisse werden als Quellenangaben wie Zitate und Metadaten geliefert. Die Suche funktioniert über klassische Keyword-Suchen oder über Vektor-Ähnlichkeitssuchen.
- Generation: Auf Grundlage der Suchergebnisse generiert der RAG Chatbot eine fundierte Antwort und fügt Quellenangaben hinzu. Dies minimiert das Risiko von „Halluzinationen“, bei denen Sprachmodelle falsche Informationen liefern.
Keyword-Suche vs. semantische Suche im Kontext von RAG Chatbots
Die klassische Keyword-Suche stößt im Kontext von RAG Chatbots an ihre Grenzen. Sie basiert auf der exakten Übereinstimmung von Begriffen und ignoriert semantische Zusammenhänge. Dies führt dazu, dass nicht selten relevante Informationen übersehen werden, weil z. B. die Wortwahl in der Suchanfrage nicht exakt mit der in den Dokumenten übereinstimmt. Diese Limitierung wirkt sich direkt auf die Qualität der Antworten aus. Sie können zwar Synonyme und Schreibweisen manuell vorbereiten, doch das ist mühsam und unzureichend, da ein tiefes Verständnis des Kontexts fehlt.
Embeddings und Vektordatenbanken: Der Schlüssel zur semantischen Suche
Für eine semantische Suche wandeln Embeddings Texte in numerische Vektoren um, die die Bedeutungsbeziehungen zwischen Wörtern und Sätzen abbilden. Dieser Vorgang wird auch „Tokenization“ genannt. Eine Suchanfrage wird ebenfalls in einen Vektor überführt, und die Vektordatenbank identifiziert Inhalte mit ähnlicher Bedeutung. So können Sie Informationen finden, die der Anfrage semantisch nahekommen, auch wenn die exakten Begriffe nicht übereinstimmen.
Tool Usage: Wie KI-Tools Prozesse verbessern
Ein herausragendes Merkmal von RAG Chatbots ist die sogenannte „Tool Usage“. KI-Modelle können externe Aktionen durchführen, wie etwa das Erstellen von Kalendereinträgen oder das Aktualisieren einer Confluence-Seite. Das Sprachmodell muss dafür nicht explizit für jedes Tool trainiert werden – eine klare Beschreibung der Funktion und Parameter des Tools als Teil des Prompts reicht aus, um es in den Prozess zu integrieren.
Limits und Learnings von RAG Chatbots
- Vereinfachter Zugriffs-Layer: LLM-Tools brauchen eine zugängliche Zugriffsschicht vor den APIs, um den Einstieg zu erleichtern.
- Parameter-Validierung: LLMs verwenden Parameter nicht immer korrekt, daher ist eine Validierung unerlässlich. Detaillierte Fehlermeldungen helfen, Anfragen zu korrigieren.
- Tool-Aufrufe: Der Zeitpunkt von Tool-Aufrufen ist nicht exakt steuerbar. Irreversible Aktionen sollten nur mit expliziter Freigabe durchgeführt werden; Undo-Funktionen sind hilfreich.
- Kontext & Zugriffskontrolle: Es ist wichtig, den Kontext klar zu definieren und Zugriffsrechte außerhalb des LLMs zu regeln, um die Sicherheit zu gewährleisten.
KI-Assistenten: Kombination von Bausteinen
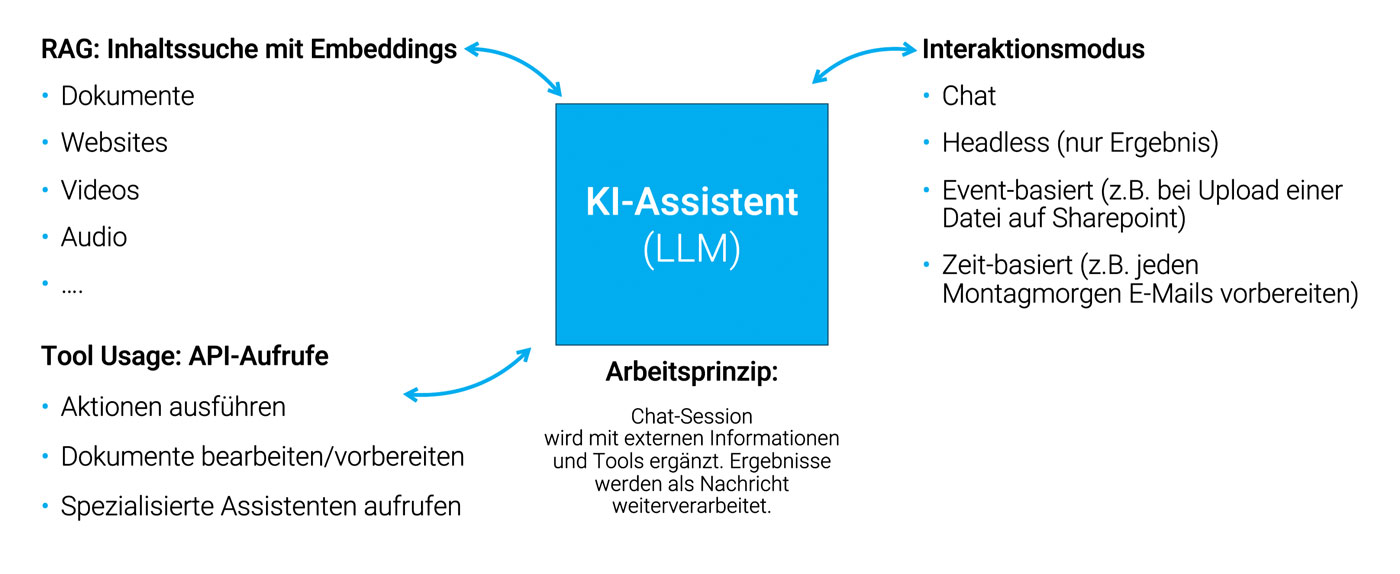
Ein KI-Assistent kombiniert Technologien wie RAG, Tool Usage und andere Interaktionen. Ein Beispiel ist ein Chatbot, der Informationen abruft, Tools nutzt und Antworten generiert. Solche Assistenten können jedoch nicht nur im Chat-Modus arbeiten, sondern auch als „headless“ Assistenten fungieren, die Aufgaben wie die automatische Berichterstellung übernehmen, ohne dass der Nutzer eingreifen muss. Beispielsweise könnte ein KI-Assistent jeden Montagmorgen automatisch Berichte generieren oder Dokumente verarbeiten, ohne dass ein Mensch aktiv eingreifen muss.
Wissensaufbereitung mit RAG
Die Grundlage eines RAG Chatbots ist eine gut strukturierte Wissensbasis. Hierbei ist es entscheidend, dass Dokumente so aufbereitet werden, dass sie von der KI verarbeitet werden können. Dieser Prozess lässt sich in zwei Schritte unterteilen: Verschriftlichung und Chunking.
- Verschriftlichung: Texte müssen in einer zitierfähigen Form vorliegen: Bei Textdokumenten ist dies einfach, bei Audio- oder Videodateien müssen Sie zunächst eine Transkription erstellen. Dafür gibt es bereits gute Spracherkennungsmodelle, aber unter Umständen müssen Sie die Transkription manuell bereinigen (Füllwörter etc.), um den Text lesbar zu machen. Bei der Arbeit mit Bildern kann es sinnvoll sein, OCR (optische Zeichenerkennung) oder Bilderkennung einzusetzen, um den Inhalt zu extrahieren. Falls bereits eine Bildunterschrift in Ihren Quellen vorhanden ist, kann das ausreichen. PDFs, Websites und Slidedecks lassen sich in das einfache Textformat Markdown umwandeln und dort weiterbearbeiten.
- Chunking: Beim Chunking werden längere Texte in kleinere Einheiten („Chunks“) aufgeteilt. Ziel ist es, den Kontext auch bei längeren Dokumenten zu bewahren und gleichzeitig sicherzustellen, dass die KI in der Lage ist, den Inhalt sinnvoll zu verarbeiten. Das ist eine Herausforderung bei der Generierung eines Embeddings: Einerseits möchte ich immer einen Verweis auf eine konkrete Stelle im Quellmaterial, auf der anderen Seite hat ein Embedding-Vektor immer die gleiche Größe (1.500 Zahlen). Ein typischer Chunk umfasst etwa ein bis zwei Absätze, oder 100 bis 200 Wörter oder 500 bis 1000 Zeichen. Die Feinheit des Chunking-Prozesses kann je nach Dokument und Kontext variieren. Ein zu großer Chunk verliert semantische Details, ein zu kleiner Chunk verliert den Zusammenhang. Da gibt es kein Patentrezept, dass muss individuell für jedes Projekt entschieden, getestet und evaluiert werden. Es gibt jedoch Strategien, um das Beste aus beiden Welten zu kombinieren, z.B. durch das Hinzufügen von Metainformationen oder KI-generierte Zusammenfassungen.
Vom Prototyp zum Produktivsystem
Der Weg vom Prototyp zu einem produktiven System ist oft herausfordernd. Beginnen Sie mit der Auswahl der richtigen Infrastruktur: Hier haben sich Anbieter wie MS Azure, AWS und Google Cloud als solide Lösungen erwiesen. Diese bieten Managed Services für Vektordatenbanken und LLM-Integrationen, die DSGVO-konform sind und eine schnelle Entwicklung ermöglichen.
Ein zentraler Punkt bei der Implementierung ist die nahtlose Integration in bestehende Systeme und Prozesse. Den Connector-Code, der zwischen LLMs, Datenbanken und internen APIs vermittelt, sollten Sie individuell entwickeln, damit zukünftige Änderungen oder Erweiterungen einfach umsetzbar sind. Dadurch sind Standardkomponenten wie Sprachmodelle oder Vektordatenbanken austauschbar und sie müssen nicht das ganze System neu bauen. Da sich die KI-Modelle nach wie vor rasant entwickeln, sollten Sie flexibel bleiben und sich nicht komplett auf einen Anbieter festlegen.
Wichtige Features auf dem Weg zur Produktivumgebung:
Wichtige Begleit-Features auf dem Weg in die Produktivumgebung sind Session-Storage, Verhinderung von Missbrauch sowie Feedback- und Monitoring-Möglichkeiten. Hierdurch können Sie die Qualität Ihres Systems langfristig verbessern.
- Session-Storage: Sie sollten in der Lage sein, RAG Chatbot-Sessions zu speichern, um diese später wieder aufzurufen oder zu überprüfen. Dies ist wichtig für Monitoring oder Qualitätssicherung.
- Missbrauch verhindern: Authentifizieren Sie Ihre Nutzer:innen, um Missbrauch und Überlastung zu verhindern. So können Sie auch Rate-Limiting besser umsetzen. Denn Rate-Limiting blockiert ungewünschte User:innen oder Bots, die Websiten überanspruchen oder missbrauchen. Und je nachdem wie exponiert Ihr Tool ist, müssen Sie sich über Angriffe auf Ihr Sprachmodell wie Prompt Injections und Themen-Derailment – wenn Ihr Bot dazu gebraucht wird, Schimpfwörter zu verwenden – Gedanken machen.
- Feedback und Monitoring: Nutzerfeedback, z. B. über Daumen hoch/runter, hilft, die Qualität Ihres Systems zu verbessern. Dadurch sammeln Sie einfach und schnell eine erste Zufriedenheitsmetrik, ohne in die einzelnen Unterhaltungen reingehen zu müssen.
Sie haben erste RAG- oder KI-Ideen im Kopf, aber wissen nicht, ob sie sinnvoll oder machbar sind? Jetzt KI-Workshop anfragen.
Konkrete Use Cases von RAG Chatbots und KI-Assistenten
Retrieval Augmented Generation (RAG) Chatbots und KI-Assistenten eröffnen zahlreiche Anwendungsfelder in verschiedenen Unternehmensbereichen. Auf drei Use Cases möchte ich näher eingehen:
1 Sales-Unterstützung durch RAG Chatbots
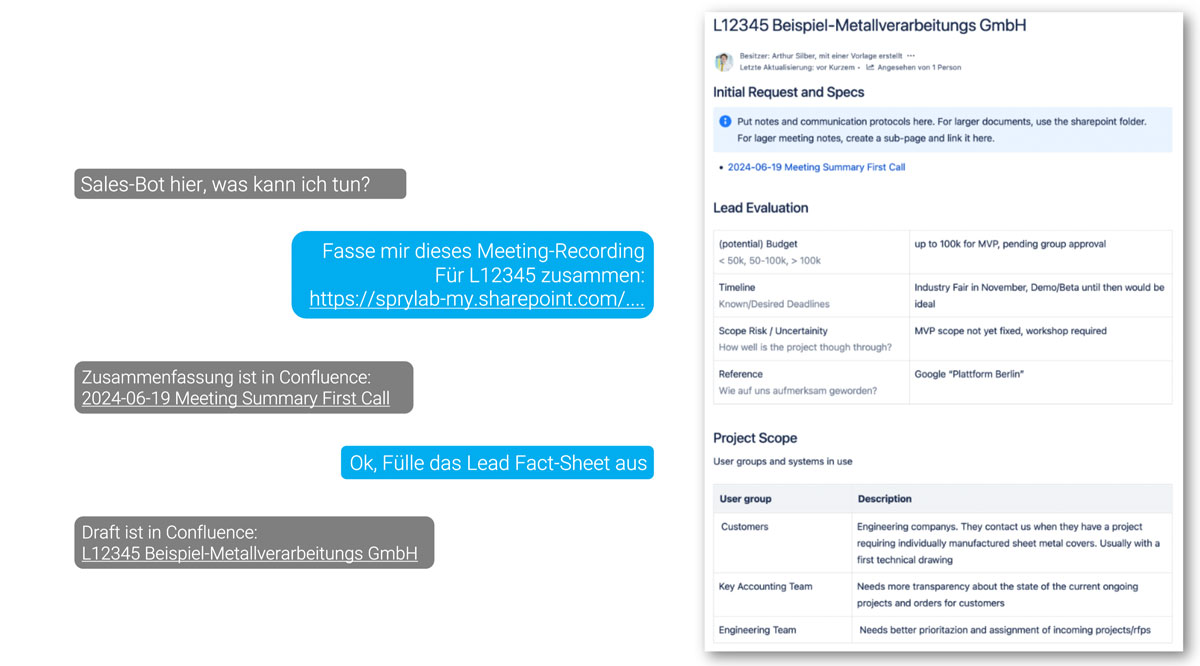
Ein besonders praxisnaher Anwendungsfall für RAG Chatbots in Unternehmen ist die Unterstützung von Sales-Prozessen. Sie können z. B. Verkaufsprozesse automatisieren, indem sie Beratungsgespräche mit Ihren Kund:innen dokumentieren, Leads verfolgen und Fact Sheets erstellen. Dies ist besonders hilfreich, um Informationen konsistent und strukturiert festzuhalten, unabhängig von den verwendeten Programmen oder Tools in Ihrem Unternehmen.
Eckdaten:
- Interaktion: Integration als MS-Teams Chatbot, bei dem der Gesprächspartner:innen direkt identifiziert wird.
- LLM: GPT-4 Turbo via MS Azure
- Angebundene Services: SharePoint File Transfer, Confluence, Whisper
- Systemarchitektur: Ein Master-Assistant führt die Chat-Unterhaltung, während spezialisierte Sub-Assistants einzelne Aufgaben übernehmen. Dies erfolgt über eine Kombination aus Prompt-Chains und individuellem Code.
Wichtige Überlegungen: Bei der Implementierung eines Sales RAG Chatbots sollten Sie den zugrundeliegenden Prozess standardisieren. Je mehr Automatisierung und Unterstützung durch einen KI-Assistenten stattfindet, desto mehr müssen die Abläufe formalisiert und dokumentiert werden. Das stellt sicher, dass der Chatbot in verschiedenen Situationen konsistent und zielgerichtet reagiert. Speichern Sie Zwischenergebnisse in Tools wie Confluence, um menschliche Überprüfungen und Korrekturen zu ermöglichen. Diese hybride Arbeitsweise erleichtert Ihnen die Integration kleinerer Korrekturen und sorgt für einen nahtlosen Workflow. Zuletzt sind Datenschutz und Compliance zu beachten, besonders wenn Meetings aufgezeichnet werden. Informieren Sie die Teilnehmenden vorab und planen Sie Speicherdauer sowie Nutzung von Transkriptionen. Mehr Infos dazu unter KI-Beratung.
2 Datenrecherche und -aufbereitung von technischen Daten
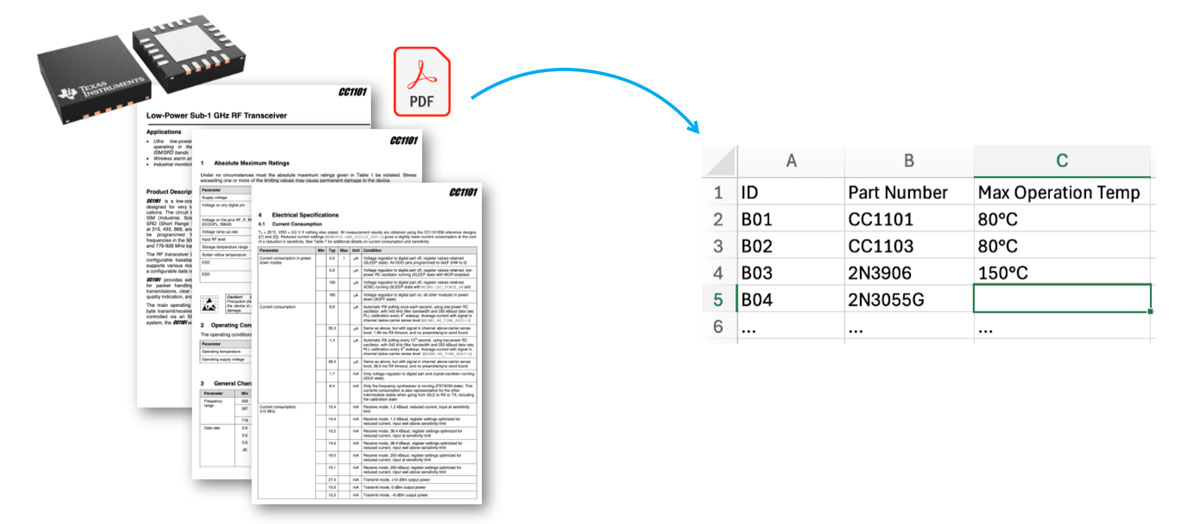
RAG Chatbots können ausgezeichnet für die automatisierte Datenrecherche und -aufbereitung eingesetzt werden, etwa in der Maschinenbauindustrie. Technische Daten oder Kennzahlen aus verschiedensten Quellen wie Dokumenten oder Datenbanken werden hierbei automatisch extrahiert und aufbereitet. Dies spart nicht nur wertvolle Zeit, sondern erlaubt es Ihren Mitarbeitenden, sich auf anspruchsvollere Aufgaben zu konzentrieren.
Eckdaten:
- Interaktion: Headless (Ausführung nach Aufruf)
- RAG-Pipeline: Die Extraktion von Text aus PDF-Dokumenten erfolgt über das Tool „unstructured“ und speichert die Daten vorübergehend in einer In-Memory-Vektorendatenbank.
- Systemarchitektur: Die Eingabe erfolgt dateibasiert (z. B. Data Sheets) oder über den Import/Export von Daten via CSV. Bei schlechter PDF-Qualität kann die Nutzung von OCR notwendig sein, um den Text korrekt zu erfassen.
Wichtige Überlegungen: Prüfen Sie die Qualität der extrahierten Daten händisch, insbesondere wenn es sich um kritische Daten handelt. Die Prüfung ist immer noch schneller, als die Daten vollständig manuell zu verarbeiten. Implementieren Sie in jedem Fall einen Freigabeprozess, denn die Verantwortung liegt letztlich bei einem Menschen.
3 Interner und externer 1st-Level-Support
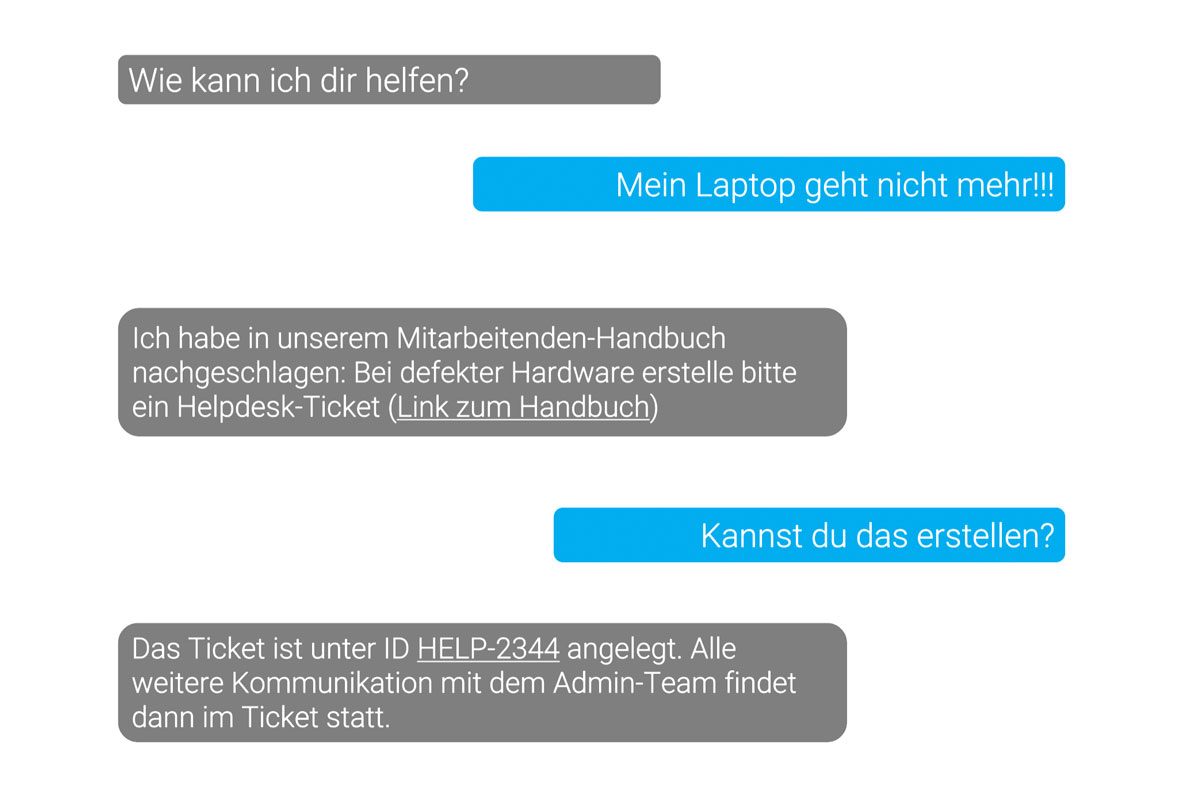
Auch im Bereich des Supports erweisen sich RAG Chatbots als äußerst nützlich. Sie können häufig gestellte Fragen automatisiert beantworten und so den First-Level-Support entlasten. Dadurch gewinnt Ihr Support-Team mehr Zeit für komplexere Anliegen, während Ihre Kund:innen schneller Antworten auf ihre Fragen erhalten.
Eckdaten:
- Interaktion: MS-Teams Chatbot
- LLM: GPT 4o via MS Azure
- RAG-Pipeline: Keyword-basierte Suche in externer Website via API-Anbindung (Eine Vektordatenbank ist noch nicht notwendig)
- Systemarchitektur: Lightweight: kein persistenter Message-Store, Unterhaltungen beenden automatisch nach fünf Minuten
Wichtige Überlegungen: Ein wesentlicher Aspekt bei der Nutzung von RAG Chatbots im Support-Bereich ist das Verhalten Ihrer User:innen: Während einfache Anfragen, wie die Lösung alltäglicher Softwareprobleme, gut abgedeckt werden, ist der Mehrwert bei tiefergehenden fachlichen Fragen größer. Hier ist es entscheidend, dass entsprechende Dokumentationen vorliegen, auf die der Chatbot verweisen kann.
Mit diesen Anwendungsbeispielen wird deutlich, wie vielseitig Sie RAG Chatbots und KI-Assistenten einsetzen können, um Ihre Unternehmensprozesse zu digitalisieren und optimieren, Mitarbeitende zu entlasten und die Effizienz zu steigern.
Wie können Sie selbst loslegen?
ChatGPT von Open AI hat mittlerweile RAG-Funktionalitäten, d.h. Sie können hier ausgewählte eigene Dateien hochladen. Testen Sie mit Ihren Dokumenten, inwiefern ChatGPT korrekte Antworten liefert. Auf ChatGPT können Sie mittlerweile sogar „Custom GPTs“ erstellen. Diese erlauben Tool Usage und das Aufrufen von Custom APIs. Das ist ideal fürs Prototyping, da Sie diese mit Ihrem Team teilen und testen können.
Während des Prototypings kann es passieren, dass Sie bestimmte Aktionen selbst händisch ausführen müssen. Auch wird sich die Interaktion und Integration noch holprig anfühlen und manche APIs werden nicht vorhanden sein, um einen Ihrer gewünschten Prozesse zufriedenstellend abzubilden. Dennoch haben Sie vielleicht durch das Testen und Erstellen eines Prototyps ein Potential für eine mögliche Prozessoptimierung in Ihren Unternehmen identifiziert und sollten in einem nächsten Schritt in die Individualentwicklung gehen.
Fazit
RAG Chatbots und KI-Assistenten bieten eine innovative Chance, den Umgang mit Daten in Ihrem Unternehmen nachhaltig zu verändern. Dank intelligenter Suchprozesse, nahtloser Tool-Integrationen und einer intuitiven Nutzererfahrung können Sie Ihre Prozesse automatisieren, Ihre Produktivität steigern und Ihre Ressourcen insgesamt effizienter einsetzen.
Für den Einstieg empfehle ich, zunächst einfache Anwendungsfälle, etwa mit ChatGPT und dessen RAG-Funktionalitäten, zu testen. Auf dieser Basis können Sie dann maßgeschneiderte Lösungen entwickeln lassen und in Ihre Abläufe integrieren. Ob Vertrieb, Support-Automatisierung oder die effiziente Dokumentenverarbeitung – Ihre Möglichkeiten sind vielfältig. Wenn Sie mehr über unsere KI-Leistungen und Ansätze erfahren möchten, klicken Sie hier.
FAQ: Häufig gestellte Fragen zu RAG Chatbots
Ein RAG Chatbot (Retrieval-Augmented Generation Chatbot) ist ein KI-gestützter Bot, der Antworten auf Nutzeranfragen durch die Kombination von zwei Prozessen generiert: Information Retrieval (das Abrufen relevanter Daten aus einer Wissensbasis) und Textgeneration. Anders als herkömmliche Chatbots, die auf vordefinierte Antworten oder einfache Regelwerke angewiesen sind, durchsucht ein RAG Chatbot umfangreiche Datenquellen wie interne Unternehmensdokumente oder Datenbanken und liefert durch Natural Language Processing (NLP) präzise Antworten in Echtzeit. Dies ermöglicht Ihnen eine individualisierte und datenbasierte Antwort auf komplexe Fragestellungen.
Retrieval Augmented Generation (RAG) ist wichtig, weil es die Grenzen herkömmlicher Chatbot-Technologie überwindet. RAG kombiniert das Abrufen von spezifischen, relevanten Informationen aus einer umfangreichen Wissensbasis mit der Fähigkeit, menschenähnliche Antworten zu formulieren. So kann der Chatbot nicht nur allgemeine, vorgefertigte Antworten geben, sondern sich auf Echtzeitdaten und den spezifischen Kontext einer Anfrage stützen. Dies ist besonders wichtig in Bereichen wie Kundenservice, Vertrieb und IT-Support, wo maßgeschneiderte, datenbasierte Antworten den Unterschied zwischen einer erfolgreichen Interaktion und Frustration machen können. RAG Chatbots finden bereits Anwendung in diversen Bereichen, einschließlich Bildungssoftware, wo sie die Wissensvermittlung durch personalisierte und interaktive Lerninhalte optimieren.
Ein RAG Chatbot bietet zahlreiche Vorteile für Ihr Unternehmen:
Effizienzsteigerung: Komplexe Kundenanfragen können schneller und präziser beantwortet werden, was die Bearbeitungszeit verringert.
Bessere Kundenbetreuung: Der Chatbot liefert kontextbasierte und personalisierte Antworten, was die Zufriedenheit und Bindung Ihrer Kund:innen erhöht.
Optimierung interner Prozesse: Ihre Mitarbeiter:innen können schnell auf Informationen aus internen Datenquellen zugreifen, was Entscheidungsprozesse beschleunigt und Wissenssilos auflöst.
Kostensenkung: Durch den Einsatz eines Retrieval Augmented Generation Chatbots kann Ihr Bedarf an menschlicher Arbeitskraft im Kundensupport oder Helpdesk reduziert werden, ohne die Qualität der Antworten zu beeinträchtigen.
Skalierbarkeit: Der RAG Chatbot kann eine Vielzahl Ihrer Anfragen gleichzeitig bearbeiten, was besonders in Zeiten mit hohem Anfragevolumen von Vorteil ist.
Der wesentliche Unterschied zwischen einem RAG Chatbot und einem herkömmlichen Chatbot liegt in der Art, wie beide Informationen verarbeiten. Herkömmliche Chatbots basieren oft auf regelbasierten Systemen oder vorgefertigten Antworten und sind dadurch in ihrer Flexibilität stark eingeschränkt. Sie können einfache Anfragen zwar effizient bearbeiten, stoßen jedoch schnell an ihre Grenzen, wenn es um komplexe oder unerwartete Fragen geht. RAG Chatbots hingegen nutzen eine Kombination aus maschinellem Lernen und der Fähigkeit, Informationen aus verschiedenen Datenquellen in Echtzeit abzurufen. Dies bedeutet, dass sie auf eine Vielzahl von aktuellen und relevanten Informationen zugreifen können und diese dynamisch in verständlicher, natürlicher Sprache formulieren. Im Gegensatz zu herkömmlichen Chatbots, die oft auf starren, vorher definierten Dialogen beruhen, sind RAG Chatbots deutlich anpassungsfähiger und in der Lage, selbst komplexe Fragen mit maßgeschneiderten Antworten zu beantworten.
Ein RAG Chatbot kann auf eine Vielzahl von Datenquellen zugreifen, darunter:
Interne Dokumente und Datenbanken: Unternehmensrichtlinien, Schulungsdokumente, Handbücher, technische Spezifikationen, etc.
Content-Management-Systeme: Produktbeschreibungen, Anleitungen und Support-Artikel.
Cloud-Speicher: Informationen aus Unternehmens-Clouds wie Google Drive, OneDrive oder AWS.
Kundenbeziehungsmanagement: Daten zu Kundengeschäften, Supportanfragen und Kontakthistorien aus Ihrem CRM und Kundenportal.
ERP-Systeme: Informationen zu Bestellungen, Lieferketten und Inventar.
Externe APIs und Datenbanken: Falls gewünscht, kann der Chatbot auch auf externe Datenquellen wie Wetterdaten, Börseninformationen oder öffentlich zugängliche wissenschaftliche Daten zugreifen. Die Integration hängt von den spezifischen Anforderungen des Unternehmens ab.
Ja, RAG Chatbots können sicher gestaltet werden, um den Umgang mit sensiblen Unternehmensdaten zu gewährleisten. Durch die Implementierung von Verschlüsselungsprotokollen, rollenbasierten Zugriffssteuerungen und sicheren Schnittstellen (APIs) wird sichergestellt, dass vertrauliche Informationen nicht unautorisierten Dritten zugänglich gemacht werden. Außerdem werden oft Mechanismen zur Datenanonymisierung eingesetzt, um sicherzustellen, dass persönliche oder sensible Daten nur dann verarbeitet werden, wenn dies notwendig ist. Regelmäßige Sicherheitsaudits und die Einhaltung von Datenschutzrichtlinien wie der DSGVO (in Europa) sind ebenfalls essenziell für den sicheren Betrieb.
Die Entwicklungszeiten eines Retrieval Augmented Generation Chatbots variieren je nach den individuellen Anforderungen unserer Kunden. Anders als bei standardisierten Lösungen bieten wir keine „One-Size-Fits-All“-Implementierungen, sondern entwickeln den Chatbot gezielt auf Ihre Geschäftsprozesse und Bedürfnisse zugeschnitten. Der gesamte Prozess – von der Anforderungsanalyse über die Entwicklung bis hin zur Implementierung – kann zwischen 4 und 16 Wochen dauern, abhängig von der Komplexität des Projekts und der Integration in bestehende Systeme. Hier ein Überblick über die wichtigsten Schritte:
Anforderungsanalyse und Konzeption: Gemeinsam mit Ihnen erarbeiten wir eine detaillierte Bedarfsanalyse, um die Anforderungen und Ziele des RAG Chatbots präzise festzulegen.
Datenaufbereitung und Integration: Die Vorbereitung und Integration der relevanten Datenquellen ist ein zentraler Bestandteil, da wir sicherstellen, dass der Chatbot Zugriff auf die benötigten Informationen hat.
Individuelle Modellentwicklung und Anpassung: Statt vorgefertigter Modelle entwickeln wir als Softwareentwicklung Agentur ein KI-Modell, das auf Ihre spezifischen Daten und Anforderungen trainiert wird. Dies kann auch das Training mit firmeneigenen Dokumenten und Datenbanken umfassen.
Testphase und Optimierung: Vor dem Live-Betrieb wird der Chatbot intensiv getestet, um sicherzustellen, dass er korrekt und effizient arbeitet. Anpassungen und Optimierungen basieren dabei auf Testläufen mit realen Szenarien aus Ihrem Geschäftsalltag.
Schulung und Support: Nach der Implementierung bieten wir Ihnen und Ihrem Team eine umfassende Schulung an, damit der Chatbot optimal genutzt und gepflegt werden kann. Zudem stehen wir für Support und künftige Updates zur Verfügung.
Die Pflege und Aktualisierung der Wissensbasis eines RAG Chatbots erfolgt kontinuierlich, um sicherzustellen, dass die bereitgestellten Informationen stets aktuell und korrekt sind. Dies beinhaltet das regelmäßige Einpflegen neuer Datenquellen, wie zum Beispiel aktualisierte Richtlinien oder neue Produktinformationen, um sicherzustellen, dass der Chatbot immer auf die neuesten Daten zugreifen kann. Es ist wichtig, den bestehenden Inhalt regelmäßig zu überprüfen, um veraltete oder ungenaue Informationen zu entfernen oder anzupassen. Darüber hinaus kann es sinnvoll sein, das zugrundeliegende Modell regelmäßig nachzutrainieren, insbesondere wenn sich die Art der Anfragen oder die Datenlandschaft des Unternehmens ändern. Rückmeldungen der Nutzer spielen ebenfalls eine entscheidende Rolle, da sie dabei helfen, die Leistungsfähigkeit des Chatbots kontinuierlich zu verbessern. Indem man auf Anfragen achtet, die nicht optimal beantwortet wurden, können gezielte Anpassungen in der Wissensbasis vorgenommen werden, um die Genauigkeit und Relevanz der Antworten stetig zu steigern.







