


In the last 10 years, the field of Artificial Intelligence and more specifically Machine Learning, one of its subsets, has progressed a lot. The emergence of new techniques like Deep Learning and a common effort to build Open Source communities, frameworks and libraries have all contributed to the advancement of AI.
More recently, Natural Language Processing (NLP), a sub-domain dedicated to the understanding of textual content, has also benefited from new architectures like the “transformers” that enable the creation of high performing language models that could be easily reused for different use cases like translation, sentiment analysis, and text classification.
For SPRYLAB, it was therefore totally logical to build and offer innovative features that allow publishers to take advantage of these recent developments. Therefore, we started working on a set of APIs that would form the basis of our Purple DS ACM (Autonomous Content Management) offering. We decided to choose recommendation systems, article linking and topic modelling (TP) as first use cases to build our ACM solution. Let’s take a closer a look at these use cases.
Use case #1: Recommendation system
As a digital publisher, you constantly face the challenge of attracting a loyal online audience to build a successful brand. The best way to address this problem is by providing impactful and personalised content that keeps the user engaged. Recommendation systems (RecSys) enhance user experience, increase page views, and improve site ranking. RecSys are quite popular and subject to a lot of research. They can be implemented using various approaches alone or together, the most popular ones being content-based filtering and collaborative filtering.
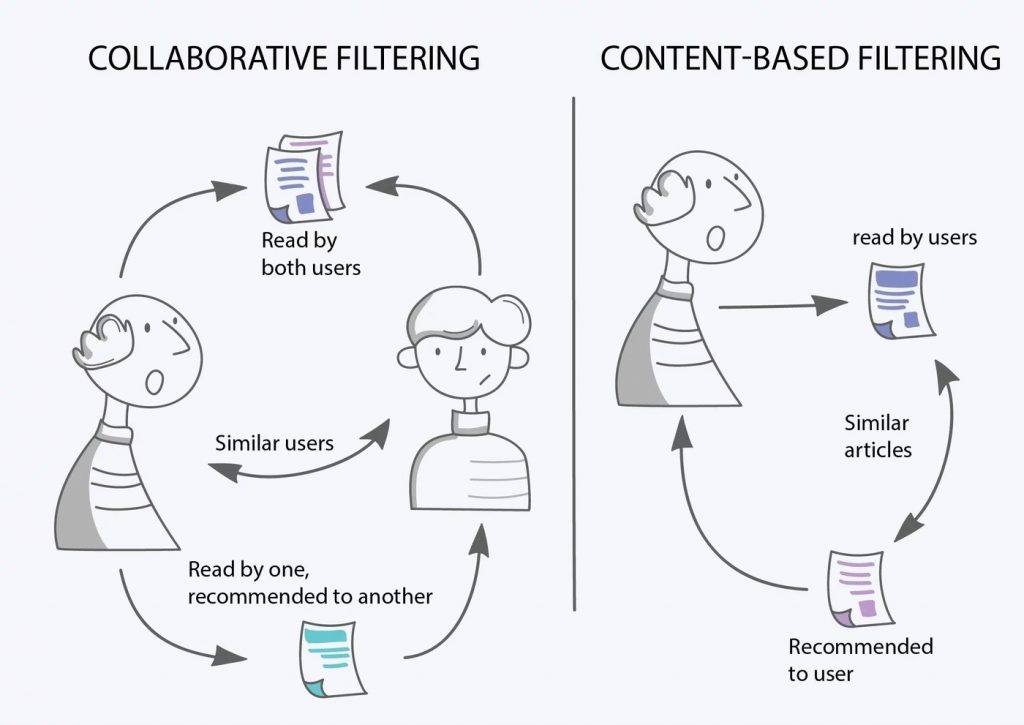
Content-based filtering
Content-based filtering is a technique which analyses what a given person is reading and tries to prioritise similar content. This means that the articles that would be recommended are matched to the personal preference based on the history of reading and the current reading. To be able to define the preference of a user, we need to be able to identify which information (often called features in ML) can be used or inferred from the articles readers are interested in. In our case, features such as category, sub-category or more refined topics are available or could be derived from other NLP techniques.
Collaborative filtering
Collaborative filtering is a technique which not only considers an individual’s article preferences but also incorporates the data of other readers with similar preferences. Compared to content-based filtering, the diversity of the content that could be recommended to the reader is much higher. Moreover, it is not necessary to compute the similarity between different articles.
Ensemble learning
Like many machine learning systems, we often see an increase in accuracy if we combine the results of different models. This technique is called ensemble learning. We are implementing such a hybrid system in our RecSys.
In terms of implementation, it is extremely important to have a proper data ingestion and transformation pipeline to be able to train our models. Indeed, the amount of data in terms of reader analytics is rather significant. At SPRYLAB, we decided to use a modern and flexible framework to perform these tasks: Apache Beam. This enables us to have a single framework that can handle both Stream and Batch data pipelines using the same API. It is also independent from its execution platform so that you can use your own Spark cluster if you already have one available. If you would like to reduce your DevOps load, you can use an autoscaling service like Google Dataflow.
Lastly, to continually improve our performance and quality, we are evaluating several possible improvement paths:
- Certain topics which are subject to seasonal interest could easily be captured and reflected in our model
- A reader might be affected by a fixed strategy in terms of preferences. By using a proper reinforcement learning technique, we might be able to strike a better balance between exploration and exploitation. This technique consists of alternating different strategies at the right frequency.
Use case #2: Article linking
Other goals common to all digital publishers are to keep audiences engaged and to increase visibility by improving SEO. This could be achieved by linking part of an article (typically a group of words in a sentence) to either another article or to an external website.
Traditionally, this task is done manually by the editor. Needless to say, the whole process is time consuming and requires a lot of knowledge. Again, machine learning can be used to help the editor with this task by automating the generation of potential link candidates.
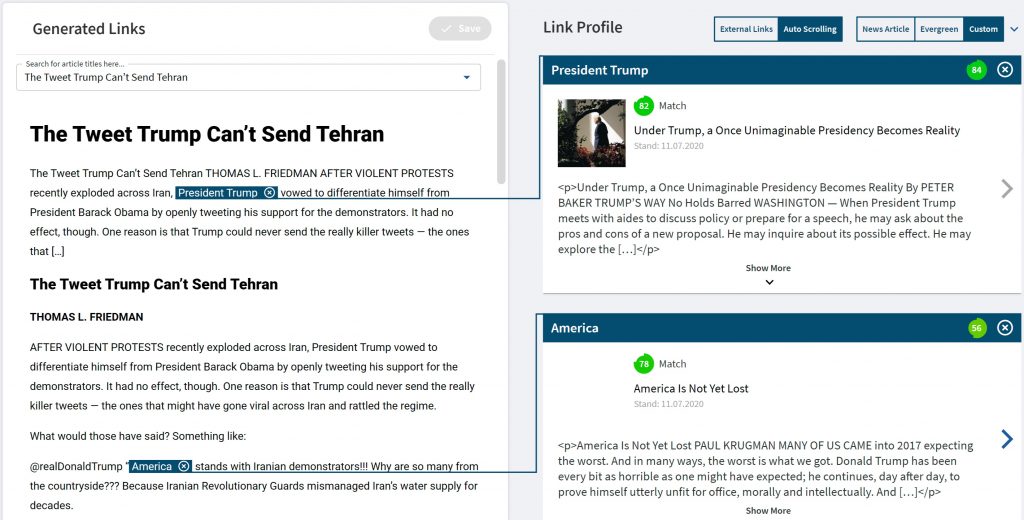
Let’s break this down a bit further and see what needs to be done:
- For any article, we need to identify the text selection that could be used as link.
- For each text selection, a proper search needs to be performed returning candidate linked articles.
- A reranking of those candidates needs to be computed.
- Lastly, a filter is applied to the results that takes into account configuration parameters such as the number of links per paragraph and the confidence threshold.
Step 1 – Text selection
The first step is a very difficult one since the number of candidate text selections suffer from combinatorial explosion very quickly. To circumvent this, our first approach is to consider only a phrase (a group of nouns) coupled with the result of a Named Entity Recognition (NER) algorithm. This greatly reduces the number of searches but has the drawback of generating selections which can be too general. For example, if a selection is referencing “The EU”, we might get a lot of search results that match the selection but not really the context. Luckily, we have a dataset of annotated selections that enables us to train a model that uses Part of Speech (POS) tagging analysis to ensure a larger and more appropriate selection.
Step 2 – Search for linkable assets
Since we are using Elasticsearch (ES) to index our content assets, the second step is currently the easiest one. Its powerful engine delivers good results that will be further refined in the next step.
Step 3 – Semantic similarity ranking
The third step takes into account some predefined strategy parameters like recency and similarity to the target article amongst others. The most interesting part comes from the similarity computation. Indeed, even ES is not able to perform well when it comes to semantic similarity, but hopefully the latest language models like BERT are able to generate embeddings that can take this into account. In the near future, we will be evaluating a way to use these embeddings to perform an efficient vector similarity search as described here.
Step 4 – Final ranking
The last step is also a quite trivial one where the final results are ranked a final time by a set of additional parameters, like number of links per paragraph, confidence level threshold, number of candidate articles, and so forth. This helps reduce the amount of links which are displayed for validation.
Note that, in our tool, if an editor is not satisfied with the automatic text selection process, he or she is still able to automatically find relevant articles when selecting any part of text.
Use case #3: Topic modelling
We already briefly mentioned Topic Modelling (TP) as a feature extraction mechanism that can be applied to the Content Filtering method when implementing a RecSys strategy. But of course, its potential use spans far beyond that.
As a publisher, you are always looking to cater to your readers’ interests and provoke their curiosity. For that purpose, you have to pay particular attention to your editorial line and the global coverage of topics you plan to integrate.
Topics of interest can at least be broken down into two categories:
- Seasonal topics which are recurring subjects that “need” to be addressed, for example events such as Christmas or the summer holidays.
- Hot topics which are current or emerging subjects that are not usually covered but are linked to your content.
We therefore decided to focus on these kinds of TP to guide editors to pick the right subject at the right moment and help them to plan their editorial calendar further in advance.
Unsupervised learning techniques
From a technical perspective, both TP categories use a common underlying mechanism which is keyword extraction. In our case, we use well-known unsupervised learning techniques like Latent Dirichlet Allocation (LDA) to extract keywords from our content databases, and more particularly, the implementation provided by a popular library called Gensim (https://radimrehurek.com/gensim/index.html). In summary, LDA enables the extraction of keywords that can be interpreted as probability distributions over words.
On top of that, we are building two main services: Seasonal Topic Analysis and Hot Topic Analysis.
For Seasonal Topic Analysis, we are able to conduct some temporal analysis for a given list of topics that we previously computed. Google Trends provides us with insights for each keyword that guides our topic selection.
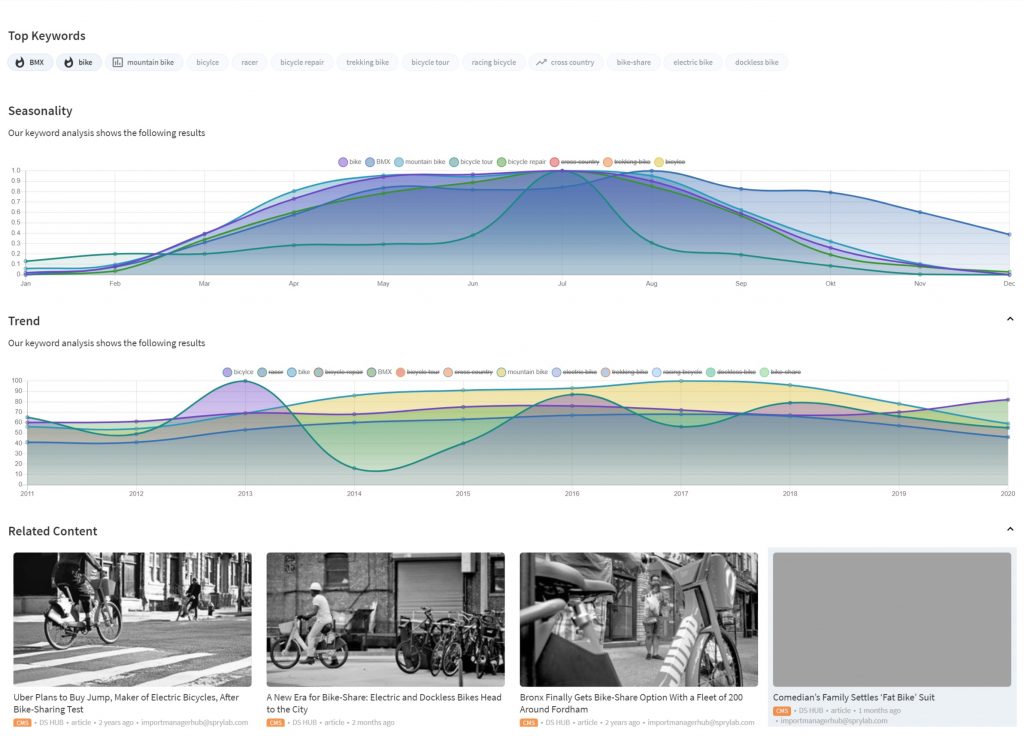
For Hot Topic Analysis, we are applying a similar strategy as in the previous case. Here, we are using the news service API Aylien to conduct a trend analysis of the captured news. We are then able to assess the relevance of the news to the topics that the publisher is mainly focused on.
In both cases, once a topic has been chosen, we provide additional features in our Purple DS article editor to easily assess the matching between the topic a user is supposed to write on and the targeted keywords relating to the topic in question.
Conclusion
Even though the second digital transformation with Machine Learning systems has only started recently, its adoption by major publishers is being gradually seen across the whole sector.
The features highlighted in this article represent only a fraction of what is possible. Indeed, in NLP, the constant progress and the emergence of even more performant language models will soon enable features such as text summarisation, or even text generation for some simpler cases. Additionally, another ML Domain like computer vision could be easily used in conjunction with NLP to further enhance existing features like linking content to image providers or creating new content such as automatic images or video annotations.




